CDデータベース制作覚え書き
鷺澤伸介(初稿 2021.1.11)
引用・リンクに制限はありません。何かお気づきの点がございましたら こちら よりご一報ください。
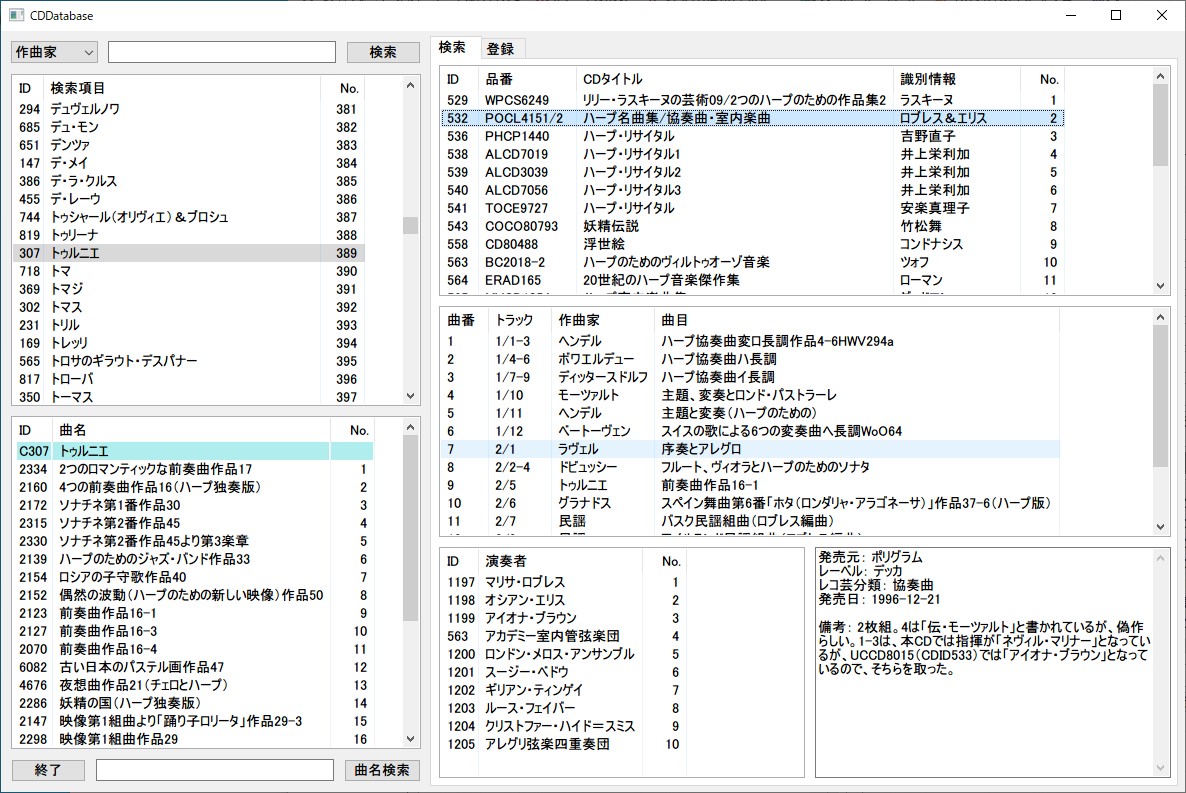
検索画面(Windows版wxWidgets3.1.4とSQLite3使用:C++、未完成)
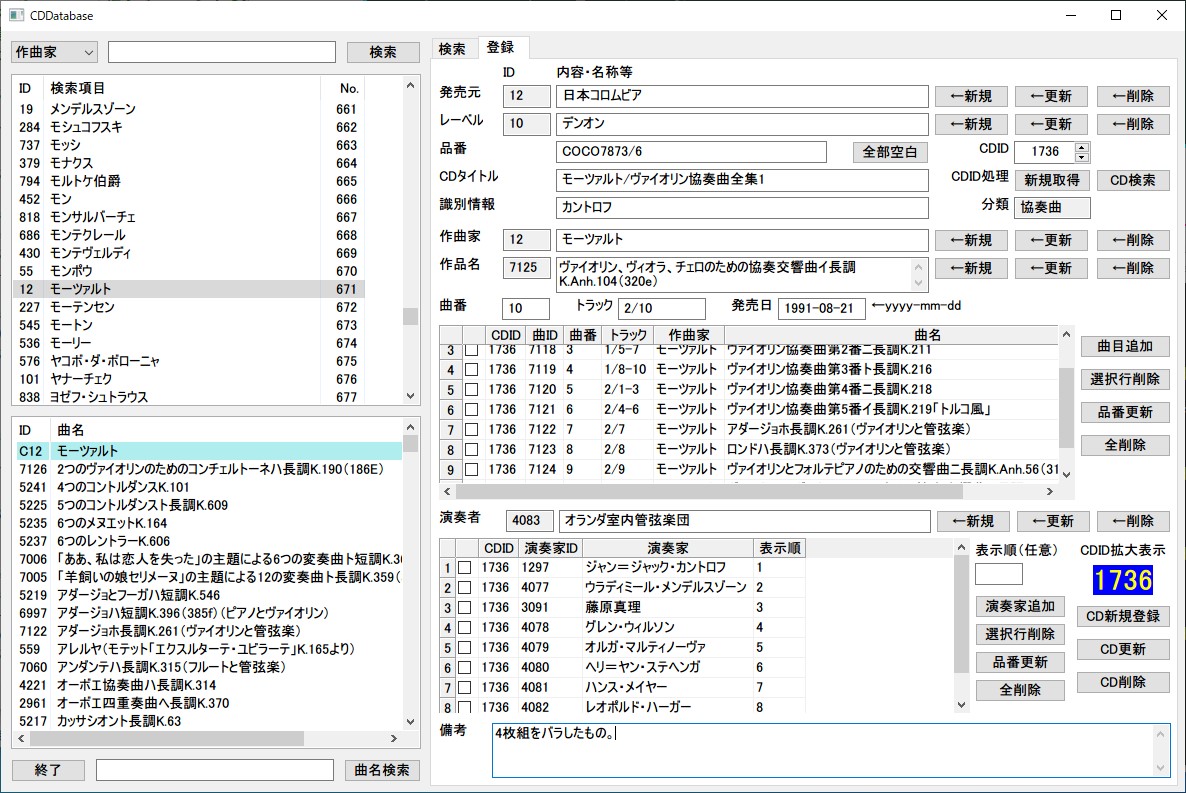
登録画面(Windows版wxWidgets3.1.4とSQLite3使用:C++、未完成)
【2023.09.20追記】
Rustに触った記録をアップしました。いちばん下のリンク「Rustプログラミング覚え書き」からどうぞ。
【2023.08.26追記】
一連のSQLite3関連のコードに不適切な点がありましたので、すべて訂正しました。具体的には、
・SQL連続処理のループで、プリペアドステートメントの生成&解放をループ外に置いてしまっていたので、最後のものしか解放されなかった。
・それでも、データベースを閉じるときにメモリ上のガベージを解放してから閉じてくれるsqlite_close_v2を使っていれば問題なかったのだが、無印sqlite_closeを使っていたため、C/C++で陥りやすい解放忘れによるメモリリークの危険を招いていた。
・sqlite3_column_textの挙動を誤解していた。公式(英語)によると、sqlite3_column_textが返すデータには常に「\0」が付けられるとのことだが、データがNULLだった場合はNULLポインタが返るとも書いてあるので、そのときはそのNULLポインタを空の文字列などに変換しておかないと、string型オブジェクトに格納するときにエラーが発生する。
C/C++には上の1・2番目みたいなミスが常につきまとうわけですから、やはり時代はRustなんでしょうかね。Rustには、ごく最近になってやっと触り始めています。インストールするかどうかにずーーーっと迷っていたのです。C/C++なら、MinGWにしてもClangにしても、今はWindowsでも圧縮ファイルを解凍するだけで使えるし、どちらのフォルダも1GBもありませんから気楽なものです。MSYS2を使うなら、Linux同様インストールコマンドを打つだけですから、もっと簡単です。ところがRustは、Rust本体以外にC/C++コンパイラが必要で、Windowsで使うのならクソでかいMicrosoft C++ Build Toolsをインストールすることが第1選択肢として推奨されているのです。ネット上では日本語でも英語でも、「RustをWindowsで使うのなら、悪いことは言わないからMicrosoft C++ Build Tools版(msvc版)にした方がよい」という助言が多いのですが、そうするためにはストレージが何GBも、へたをすると10GB以上も占有されることを覚悟しなければなりません。さんざん迷ったあげく、結局Rustはgnu版であるMinGW依存版とMSYS2版を使うことにしました(MSYS2版は、MinGW用もClang用も、それらのtoolchainではなくベーシックなパッケージを入れただけの状態でもインストールできましたが、rustupは使えないようです)。そもそもRustが使いこなせるようになるかどうかも分からないのだから、クソでかいMicrosoft製キットをインストールするのはgnu版に不満や不足を感じてからでも遅くはありません。もしmsvc版にするのなら、RustのインストーラーにC++ Build Toolsも一緒にインストールする選択肢がありますから、多くのサイトで紹介されているような、それぞれを別にインストールする方法よりも、全部Rustインストーラーに任せてしまった方が容量的には得になりそうです。Rustそのものは二つのフォルダをユーザーフォルダにコピーするだけで、.cargoフォルダが180MBくらい、.rustupフォルダが1.5GBくらいで、両方で2GB弱といったところです。そのフォルダをCドライブルートやDドライブなどに移動したい場合は、手動で二つのフォルダを移動してから、やはり手動で環境変数を設定し直すことになりますが、やり方はPC初心者でも慎重にやればできるほど簡単です(インストールの途中でインストールフォルダを移動する方法が英語で説明される……書き込まれたPathを書き直すだけでなく、新規に二組の変数&値を書き加える必要がある)。で、Rustに触ってみた印象は、はっきり言ってC++よりもさらに難しいと感じました。私のように主としてボケ防止のためにプログラミングで遊んでいるような人間にはむしろ向いているのかもしれませんが、それにしても「こんな難しい言語でよくこれだけ人気が出たものだ。みんな頭いいんだなあ」などとため息をつかずにはいられませんでした。これについてはそのうち新しいページを作って報告するかもしれませんし、その前にギブアップしてしまうかもしれませんw。
【2023.03.16この項のみ追記】
これはほぼ自分のための覚え書きです(内容が古くなったら消します)。
C/C++のプログラムは、簡単なものはVSCodeでビルドまでやってしまうこともありますが、基本的にはWindowsのMSYS2でビルドしています。で、1年くらい触らないままになっていたMSYS2をたまにはアップデートしなければと思い、msys2.exeを起動して-Syuuを打ってみたのですけれども、どうもうまくいきません。どうやら、自分がプログラミングから離れていた間にいろいろ仕様が変わってしまったようです。自作CDデータベースは今のところ特に問題もなく使えているので改造する気はないものの、WindowsやwxWidgetsのバージョンが上がっていくと今のコードのままではビルドできなくなるかもしれませんから、それを時々検証するためにも、環境はできるだけ新しく保っておきたいところです。そこで、この際だからMSYS2もwxWidgetsも全部新しく入れ直すことにしました。MSYS2は、前回同様インストーラー版は使わず、tar.xz版(msys2-base-x86_64-20230127.tar.xz)を適当なフォルダに解凍してmsys2_shell.cmdを実行してから使用を開始しました。古い方はフォルダ名に「_old」を付けて残してあります。wxWidgetsは、前回はconfigure・make・make installというオーソドックスな方法で時間をかけてインストールしましたが、MSYS2を使うならパッケージ版もあるとのことなので、今回はそちらを試してみることにしました。以下、気づいたことを箇条書きにしておきます。
MSYS2はMinGWとClangとucrtとで環境を分けるようになっていた。
MSYS2のminttyのデフォルトがShift-JISになっていた。
C++の実行ファイルから画面表示させたテキストをエディタなどにコピペすると、右端折り返しで改行コードが入ってしまう。
wxWidgetsのパッケージ版は、MinGW版・Clang版とも特に問題なし。
△……1.は、GCCとClangを両方使いたければ、GCC用とClang用とでターミナルを二つ起動しておかねばならなくなったため、少し面倒になりましたが、まあ仕方ないのでしょう。というのは、ucrt用にはどちらも入れることができたのですが、コードによってはビルド時にコンフリクト?(「ファイルはあるけれどサイズが違うのでコンパイルできないよ」というエラーメッセージが出る)が生じることがあったからです。同じコードをGCC用とClang用でビルドしても、そのようなエラーは起こりません。やはり、GCCとClangは環境を分けておいた方が無難なようです。
×……2.は、今回いちばん戸惑った点です。オプションを「ja_JP・UTF-8」に設定しているのに、日本語表示プログラムで文字化けが生じるので、まさかと思いつつchcp.comを打ってみたら、何と932(Shift-JIS)! 古い方でも試してみましたが、こちらはちゃんと65001(UFT-8)でした。コマンドプロンプトやPowerShellの文字コード問題が嫌でMSYS2を使っているようなところもあるというのに、これじゃあ……。私の環境だけの問題でしょうか? インストーラー版を使えば大丈夫とか? ともあれ、起動するごとに毎回chcp.com 65001を打つのもウザいので、homeフォルダ内にある「.bashrc」の最下行に「chcp.com 65001」と記入しておくことにしました。
×……3.も、「何じゃこりゃ?」という問題です。C++プログラムを実行して長めのテキストがターミナルに表示されるような場合、それをコピペすると、折り返しの位置に改行が入ってしまうのです。これも古い方では見られない現象です。とはいえ、catコマンドでテキストを読み込む場合はこの現象は起こりません。また、テキストファイルに書き込む場合も大丈夫でした。ふ~む、それならばと、実行時に「./a | tee x.txt」のようにして、teeコマンドで画面表示とともにテキストファイルにも書き込むようにしてみました。二度手間にはなりますが、それでできたテキストファイルをcatで読み込めばいいかと思ったのです。ところが、このようにtee付きで実行した場合は、そのまま画面表示をコピペしても余計な改行が入らないことが判明しました。teeの後に何も書かなければ当然テキストファイルは作られませんが、それでもエラーにはならないので、不要なテキストファイルを作らないためにはその方がいいかもしれません。
○……4.は、今回唯一の収穫と言ってよさそうな事柄です。wxWidgetsは、MSYS2のリポジトリに種々パッケージが用意されていることに、前回インストールした後に気づきました。そこで、今回はそちらでやってみようということで、GCCとClangのベーシックなパッケージ(mingw-w64-x86_64-gcc、mingw-w64-clang-x86_64-clang)をインストールした直後、まずGCC版の方でpacman -S mingw-w64-x86_64-wxwidgets3.2-mswを実行したところ、2分もかからずあっけなく完了しました。続いてClang版(mingw-w64-clang-x86_64-wxwidgets3.2-msw)もインストールしましたが、両方でたぶん5分もかからなかったと思います。どちらもSQLite3が同梱されていましたから、それをインストールする手間も省けました。パッケージ版は、configure時にいろいろオプションを付けたい人には不向きかもしれないけれど、wxWidgetsのコードをビルドするとき、ビルドコマンドの``内にwx-config-staticを指定しておけば、-staticオプションを付けてもエラーになることなく静的リンク実行ファイルが作れましたから、私的にはこれで十分でした(このパッケージではwx-configは3個あり、wx-configとwx-config-3.2はたぶん同じ内容で、静的リンク実行ファイルが必要ないのであればこのどちらかを指定する)。自作CDデータベースの場合は、GCCよりもClangでビルドした方が速く、また実行ファイル(静的リンク)も3/4ほどに小さくなったので、今後wxWidgetsを使う場合は、ビルドにはClangを優先して使いたいと思います。……ただ、今はC++よりもRustに興味が湧いているので、もしCDデータベースがRustでもいけそうだと思ったら、そちらでまた作り直すかもしれません。
【2021.12.25改訂】
SQLite用クラスを大幅に書き換えたので、こちらも書き直しました。
ありそうでないもの──CDデータベース
「《ウィーンの森の物語》の模範演奏」にもちらっと書きましたが、増え続けるCDに手を焼くようになってからすでに長い年月が過ぎました。東日本大震災の前後くらいから同じものを二度買いしてしまう事故がちらほら発生し始めたため、面倒でもきちんと管理する必要性を痛感、自分用の整理ソフトを作ることを思い立ちました。世の中にありそうでないもの──まったくないわけではないのですが、なかなか定番のようなものが生まれなかったのがこの「CDデータベース」です。その状況は前世紀からずっと変わらないのだから、自分にとって使いやすいものを自作するしかないのだろう……家にあるCDはクラシックがいちばん多いので、まずクラシック用を作ってみて、余力があればその他のジャンルのものも作ればいいかな……そう考えて、クラシック用データベース制作に取りかかりました。
最初(2012年頃)は「なでしこ」(クジラ飛行机[=くじらひこうづくえ]さんが作った日本語プログラミング言語)とSQLite3でやってみました。それまでプログラミング言語といえばExcelのVBAしか知らず、なでしこもSQLも初めて触れる言語だったので勉強が必要でしたが、数週間かかって自分的にまあまあ使えるものができたように思われ、以来、そのなでしこ版管理ソフトでCDの登録や検索を行ってきました。
★当時、Accessなら多少はいじった経験があったのですが、どういうわけかAccessを使うのには常に抵抗感がつきまといました。Excelをいじるのは大好きなのに……。それは現在でも変わっていません。
★なでしこ版は、データの中に半角スペースが入っていると動作がおかしくなるという現象が見られ、その回避方法も分からなかったので、入力のときに半角スペースが混じらないよう注意する必要がありました。「データには欧文は用いず、日本語と日本の文字で登録する」という原則を立てていたためあまり問題は起こらなかったとはいえ、もし欧文入力を認めていたら使えなかったかもしれません。それゆえ、別の言語でできそうなら作り直そうとかねがね思っていたのです。……なでしこをディスっているわけではないので念のため。「CDデータベースなでしこ版」は、十年近くも便利に使い続けたのですから、なでしことクジラ飛行机さんにはいくら感謝してもしきれないくらいですm(_ _)m。
その後、比較的最近になってからC/C++の基礎を勉強する機会がありました(2017年頃、独習)。そして、これらを知っていれば使うことのできるGUIライブラリがあることも知り、また最近流行のPythonにもちょっと触れてみたいという気持ちもあって、2020年11月、老骨に鞭打って重い腰を上げ、およそ8年ぶりにCDデータベースを新作することにしました。
試したのは、①PythonとTkinter、②C言語とGTK3、③C++とwxWidgetsの三組で、データベースはすべてSQLite3としました。ほかのデータベースの採用は考えませんでした。MySQLやPostgreSQLはサーバー必須だし、すでになでしこ版で1000組以上入力したSQLiteデータベースがあったからです。二週間くらいかけて①→②→③の順で試用してみたところ、結果は下記のようになりました。
PythonとTkinter ……Pythonに触るのは初めてだったが、ネット上にたくさんの情報があって疑問点はすぐ調べられるので、あまり悩むことはなかった。コードの記法は確かに簡単で、流行するだけのことはあると感じた。SQLiteとWindows間の文字コードの違いもきちんと吸収してくれるし、SQLiteの操作もなでしこ並に短いコードで済むので使いやすかった。便利な分、CやC++よりも処理が遅いと言われているが、そんなに遅いか? 体感的には分からなかった。ただし、Tkinterは今イチで、これのためにPythonの採用は見送らざるを得なかった。なでしこのGUIツールの方がやりたいことができた印象。C言語とGTK3 ……SQLiteもGTKもC言語で書かれているので、この組み合わせがSQLiteとの親和性は最も高いらしい。Pythonが選択肢から落ちた後は、特に問題がなければこれを採用する気満々だった。ところが、GTKは意外と柔軟性に欠けることが判明。データ表示に多用することになるツリービュー(データを表のように並べるツール)では、選択された行の文字列を得るだけでも面倒な処理が必要になるし、カラムの幅の最小値を13ピクセル以上にしておかないとフリーズするし(これはGTKのバグだろう)、行内の余白を少なくしようと思ってもできないし……。また、ツリービューの作り方も独特で、どうやればいいのか何時間も悩んだほど。イベントの処理も、wxWidgetsに比べると神経を使う必要があった。C++とwxWidgets ……自分のような文系人間にはC++はとても難しいのでできれば避けたい組み合わせだったが、消去法的にこれしか選択肢がなくなった。wxWidgetsをPythonから使うという手もあるけれど、wxWidgetsはC++で作られているとのことなので、この組み合わせが最もパフォーマンスが高いのではないかと判断。それに、難しいとはいえC++は一応基本を勉強した経験はあるのだから(クラスを作ったことはないというレベルだが)、Pythonよりは速く進められる可能性が高い。wxWidgetsは、個人的にはTkinterやGTK3よりもやりたいことができる印象。なでしこなら簡単にできたことがwxWidgetsではできないというケースもあったが、工夫次第でどうにかなりそうな感触はあった。
★GTKのツリービューは、「スクロールウインドウ」に「ツリービュー」という枠組みをはめ込み、さらにその中にデータを格納する「リストストア」、列を生成する「カラム」、セルの描画を司る「セルレンダラ」などをそれぞれ作ってセットしていくといった感じで、その手順の多さには大いに戸惑いました。また、例えばセルに色を付けたければ、リストストアにあらかじめ色指定用の列を用意しておき(2列の表なら、データ列とは別に3列目を作ってそこに色情報を書き込めるようにしておく)、カラムにはデータのほかその色情報用列も同時に投影する(カラム1に色を付けたければデータの1列目と色情報の3列目を同時に割り当てる)、みたいな操作になります。何だってこんな面倒な手続きになっているんだ? という感じですよねw。
かくして、C++ & wxWidgets & SQLite3の組み合わせで、あらためて制作を開始したのが2020年12月初旬。これを書いている2021年1月上旬現在、まだいろいろ詰めなくてはいけない箇所があって完成していませんが、最低限の検索・登録・更新・削除ができるところまでは到達しています(上の画像参照)。なでしこ版のときは、ある程度のことができる段階まで作ったら、「これは直そう」「こうした方が便利かな」と思っていた箇所も結局そのままになってしまいましたから、今回もそうなる可能性はかなり高いw。C++はとても難しいですし、できればあまり近づきたくないというのが正直なところなのです(プログラマの皆さんは、よくもまあこんな難しい言語を使いこなしていらっしゃるものだと本気で感心します)。ともあれ、本稿はその苦労の覚え書きです。
★アニメ『NEW GAME!!』の桜ねね──C++を勉強し使いこなせるようになる若い女の子アニメキャラ──の存在が、難しいC++学習の励みになりました(特に2期第3話)。そういえば、『小林さんちのメイドラゴン』のエルマも、『「超」入門オブジェクト指向』なる書物を「ふ~ん、なるほど~」と言いながら勉強しているシーンがありました(第12話)。正体はドラゴンであるエルマはともかく、あの子供っぽいねねっちでもゲーム開発ができるくらいにC++がマスターできるのなら、「くっそう、俺だって!」という感じですw。架空の人物だというのに、アニメの影響力にはすごいものがあります。
SQLiteの実行コードが長い!──短いコードでSQLiteが動かせるクラスを作る
C/C++となでしことで大きく異なるのが、SQLiteの操作でした。なでしこは「SQL文記述→SQLite開く→SQL文でSQL実行→SQLite閉じる」とわずか数行でSQLを実行することができるのに、C/C++では次のような長いコードを書かなければなりません。
★上記のコードで、リストコントロールに値を格納するループでカウンタがlong型なのは、wxWidgetsのwxListCtrlのアイテム番号(=行番号)がlong型だからです。リストコントロールは、新たな行を挿入すると(↑InsertItemの箇所)その行番号をlong型で返すので、
long row = MyList1->InsertItem(i, id);
MyList1->SetItem(row, 1, str);
などと書くこともできます。
この例では、それぞれの段階でのエラー発生時中断処理や、返ってきた結果をリストコントロールに表示する処理まで入っているのでさらに長くなっていますが、なでしこしか知らなかった私は、まずこの面倒さに面食らいました(Pythonはなでしこに近く、ずっと簡潔に書けます)。
また、なでしこでは複数のSQL文をまとめて実行することができました。例えばINSERTやUPDATEをまとめてしたいとき、「sql = "BEGIN;(INSERT文たくさん);COMMIT;"」みたいに、複数のSQL文を「;」で区切って一つの文字列変数に格納し、「SQL文でSQL実行」を命じれば、なでしこの方で順に実行してくれるわけです。ところが、上記のsqlite3_stepではそれはできそうにありません。
SQLiteにはもう一つ、sqlite3_execというコマンドが用意されています。これは上記の sqlite3_prepare_v2 → sqlite3_step → sqlite3_finalizeの三つの処理をひとまとめにした(=ラップした)コマンドで(そういうのを「ラッパー」と言うらしい)、INSERTやUPDATEのような結果が返らないクエリの場合はこれを使う方が得策になります。SELECTのような結果が返るクエリにも使えますが、その場合は結果を処理するためのコールバック関数を別に用意する必要があります。
最初のうちは、SELECT系にはsqlite3_stepを、INSERT・UPDATE系にはsqlite3_execを、という具合に使い分けていたのですが、前者はSELECTを発行するたびに上記のようなコードを書かねばならないので、だんだんうんざりしてきました。せっかくC++で苦労して作っているのだから、なでしこみたいに「このSQLで実行」と書けばSQLを複数まとめて処理してしまえるようなクラスは作れないものか。調べてみると、「sqlite3_execは複数のSQLをまとめて処理できる」とのこと。「あ、これはいけるかも」と思いました。
最終形としては、例えば「MySql q;」(実体=オブジェクト=インスタンス生成)→「q.SqlExec(sql, val0, val1, val2……);」などとと書けば、プレースホルダのバインドまでひっくるめて実行されてほしい。値が返る場合は「q.resultdata[0][1]」などと書けば取り出せるようにしたい。プレースホルダの「?」がいくつになるかは状況によるので、引数の数は「可変長」である必要がある。printfでおなじみの可変長引数ですが、これも調べてみるとC++11からは比較的簡単に実現できるようです。……というわけで、人生初のクラス制作に踏み切りました。作るのは初めてとは言っても、wxWidgetsはクラスの集合体のようなものですから、このライブラリを使い始めたときからすでに使う方の経験は積んでいます。それほど身構えることなく取りかかることができました。
★一応、SQLite用のC++ライブラリ(wxSQLite3、SQLiteCppなど)や、ネット上でプログラマの方々が公表されているSQLite用クラスも調べてはみました。しかし、それらを使うとしたら今度はそれらのインストール方法や操作方法を調べなくてはならないし、そもそも自分が実現しようとしているのはかなりシンプルな内容ですから、やはり自分で作ってしまった方が早いと判断しました(第一、プログラマの方々のコードは高度すぎて、私にはとても読み切れません)。それに、基礎だけとはいえせっかくC++を勉強した経験があるのだから、一度くらいはクラスを作ってみるべきだとも思っていましたしね。
……ここから、この下の「wxListCtrlのソート機能」の前までは、2021年12月改訂版となります。2020年末にゼロから作ったときは、SQLの実行には上記のように「sqlite3_exec」を使いました。それで1年間まったく問題なく使ってきたのですが、実は、せっかくプリペアドステートメントによる値のバインド処理ができるのに、それを使わないプログラムであることがずっと気になってはいたのです。自分で使うだけなのだからセキュリティに神経質になる必要はないとはいえ、使ってしかるべき機能を使わないままにしているというのはどうも落ち着かない。しかし、SQL実行に「sqlite3_exec」を使う以上は、プリペアドステートメントによるバインド処理は諦めざるを得ない。何かしら方法はあるのかもしれないけれど、その追求に時間を費やすよりは、プリペアドステートメントによるバインド処理を挟むことができる「sqlite3_step」を工夫した方が早いのではないか? そう考えて、1年ぶりに改造を試みました。
★プリペアドステートメントとは、ものすごくかいつまんで言えば、SQLインジェクション攻撃を防止できる仕組みです(SQL文をサニタイズ=無害化する仕組み)。
「sqlite3_exec」と「sqlite3_step」の比較
sqlite3_execのメリット
・複数のSQL文を一度に扱える。
sqlite3_execのデメリット
・プリペアドステートメントによる値のバインド処理が使えない。
・SELECT用にcallback関数を書かなければならない。
sqlite3_stepのメリット
・プリペアドステートメントによる値のバインド処理が使える。
sqlite3_stepのデメリット
・SQL文は一度に一つしか実行できないので、複数連続で処理するならループが必要。
・前後の処理を書かなければならないのでコードが長くなりがち。
この比較表を見れば分かるように、sqlite3_execからsqlite3_stepに乗り換えるためには、sqlite3_stepにない機能、すなわち「複数のSQL文を一度に扱う機能」を補えばよい、ということになります。
参考までに、最初に作ったクラスは次のようなものでした。
ポイントは、58行目のsqlite3_exec関数の第4引数に「thisポインタ」を指定し、37行目のcallback関数の第1引数でそれを受け取って、クラスのポインタ型にキャストする、という処理です。なぜこんなことをしているかというと、callback関数はクラスのメンバ関数にすることができないからです。よって、普通の関数からクラスのメンバ関数にアクセスするための処理が必要で、callback関数はそういう場合のために第1引数にvoidポインタを備えています。
これでもSQLは実行できます。しかし、プレースホルダへの値のはめ込みを、プリペアドステートメントを使うことなく、普通に文字列置換で行ってしまっています(90~94行目)。こういうのがSQLインジェクションの標的になるわけですね。
sqlite3_execは、①sqlite3_prepare_v2、②sqlite3_step、③sqlite3_finalizeの三つの処理をまとめたインターフェースです。複数の処理を固めたラッパーなので、①と②の間に入るべきプレースホルダへのバインド処理を挟み込むことができません。それをするためには、やはり三つを独立させる必要があります。sqlite3_stepは一度に一つのSQL文しか実行できないけれど、考えてみたら、上のような文字列置換によるバインド処理を書くのと、複数のSQL文に対応できるようsqlite3_stepをループさせる処理を書くとでのは、それほど労力は変わらないのではないか? そう思ってやってみたら、結果としてはそのとおりでしたw。ただし、①~③のコードをそれぞれ書く必要があるので、sqlite3_execよりもやはりコード量は多くなります(callback関数を書く必要がないにしても)。
最初に考えておかなければならないのは、SQL文の集合体(sql群)と、プレースホルダにはめ込む値の集合体(val群)とを、関数にどう渡すか、です。sql群は1個以上、val群は0個以上で、いずれも数は不定です。SQLiteは、複数のSQL文を一つの文字列変数にまとめて渡せば適切に分解してくれるので、sql群の方は一つの文字列でよさそうです。しかしval群の方はそういうわけにいきません。一つの文字列に固めてしまうと、自分でそれを切り分ける処理を書かねばなりませんが、値にはあらゆる文字が含まれる可能性があるので、普通の文字列と区切り記号とを完璧に区別する処理を書くのはかなり面倒です。ですから、val群の方は、引数にそのまま並べてしまうか、コンテナに分けて入れて渡すかのどちらかでしょう。sql群の方でコンテナを使うのもありです。可能性としては、次の組み合わせになります。関数名をSqlExecとし、第1引数は必ずsql群、第2引数以下がval群となります。
SqlExec(sql群=string, value=string, value=string, value=string……)
SqlExec(sql群=string, val群=vector)
SqlExec(sql群=vector, val群=vector)
いちばん簡単なのは、たぶん1.でしょう。可変長引数の処理さえ書ければいけそうですし、使うとき、値は列挙するだけでいいのでとても分かりやすい。vectorを使う2.と3.は、そこにSQL文や値をpush_backする処理と取り出す処理が必要になります。
★1.の欠点は、値の数は可変対応とはいえ、最初から数が分かっていないと使えないということです。例えば外部ファイルからSQL文と値を取り込むような場合、値の数があらかじめ判明していれば対応できますが、未知の場合、vectorに一度取り込んでからその各要素を「引数内に展開する」といったようなことはできません(少なくとも私には)。2.と3.では、vectorに取り込んだらそのまま関数に渡せばいいので、その心配はありません。……まあ、必要なら上の三つをオーバーロードで全部書いておけばいいだけの話なんですけれどね。
とりあえず1.を作ることにすると、構想はこんな感じです。
「q.SqlExec(SQL文群, value1, value2……)」のようにメンバ関数が呼ばれたら、文字列ベクターvecstrに各引数をコピーする。値はいくつ必要になるか分からないので、この関数は可変長引数にしておく。
vecstr[0]に格納されているSQL文群をsqlite3_prepare_v2に渡してプリペアドステートメントを作る。
vecstrの要素数を調べ、2以上であれば値があるので、プレースホルダへのバインド処理を行う。
プリペアドステートメントをsqlite3_stepに渡してSQL文実行。結果が返る場合はメンバ変数二次元ベクターresultdataにpush_backしていく。
vecstr[0]に複数のSQL文が格納されていたときのために、2.~4.はループ処理とする。
返った結果を使うときのため、「q.resultget().at(0).at(0)」などと書けば二次元ベクターにアクセスできるようなゲッタを備える。
第一段階。「q.SqlExec(SQL文, value1, value2...);」などと書かれてメンバ関数SqlExecが呼ばれたときに、SQL文と値を文字列配列メンバ変数に格納する処理です。プレースホルダがいくつあっても、すなわち引数がいくつあっても対応できるようにします。
★「関数テンプレートの実装はヘッダに書く」という注意は、ロベールのみならずいろいろなサイトに書かれています。こうしておかないと、かなりの確率でリンクエラーになるからです。最初、私はこれに気づかず、ずっとソースファイルの方に書いたままにしていました。普通にビルドできてしまっていたために気づかなかったのです。なぜエラーが出なかったのかというと、「巨大ファイル展開法」とでも言うべき方法でビルドしていたからでした。すべてのソースファイルのincludeだけを書いたファイルを用意し、ビルドのときはそれだけを対象にするやり方です。
●cddb.cppの中身
#include "cddb511main.cpp"
#include "cddb512.cpp"
#include "cddb513class.cpp"
#include "cddb514event.cpp"
#include "cddb515querya.cpp"
#include "cddb516queryb.cpp"
#include "cddb517queryc.cpp"
●ビルドコマンド
g++ cddb.cpp resource.o `wx-config --cppflags --libs` -static -lsqlite3
こうしておけば、全ソースファイルを読み込んで巨大な一つのソースファイルにしてからビルドする、という処理になるわけで、リンクの時間がかからないだけ大幅な時短になります(resource.oというのは、Windowsのデザインを反映させるファイルで、wxWidgets同梱のwx.rcからリソースコンパイラを使って作る)。ソースファイルを追加したりファイル名を新しくしたりした場合は上のcddb.cppの中身を書き換えるだけでよく、ビルドコマンドはいつも同じでよいのも利点です。巨大な一つのソースファイルにする、すなわち全コードが一望できる状態にしてからコンパイルするわけですから、当然リンクエラーは起こり得ません。それが、今年になって、試しにMakefileでビルドしてみるか、と思ってやってみたところ、普通にリンクエラーが出たために、初めて「あ、ヘッダに書かなきゃ」と気づいたのでした。
これで文字列ベクターメンバ変数vecstrには、「SQL文群」([0])と「値」([1]以降)が格納されます。
第二段階。再帰が止まる引数なしのSqlExec関数内で、引数の有無と、プレースホルダと値の数が合っているかどうかを確認し、問題なければsqlite3_stepを使うSqlStep関数を呼びます。ただ、これらのチェック機能はこのプログラムではあまり必要はないので、いっそのこと省略して、ここにそのままSqlStep関数の内容を書いてしまってもよかったかもしれません。
第三段階。第二段階までで準備は終わっているので、ここでsqlite3_stepその他を使って複数のSQL文を実行する処理を作ります。
★91行目のsqlite3_column_textは、データがNULLの場合は「NULLポインタ」を返します。標準C++では、元データがNULLポインタだと、char const*型にキャストしてもstring型のベクターには格納できません。ところが、wxWidgetsの文字列操作では何かしらの補助機能が働くのか、元データがNULLポインタの場合はベクターには「空の文字列」を詰めているらしく、実行してもエラーになりません(取り出してももちろん何も表示されない)。よって、wxWidgetsの場合は、データがNULLポインタだった場合は空の文字列に変更するといった回避処理を書かなくても大丈夫そうです。
★sqlite3_closeは、v2を使えば、解放していないデータがあっても解放を試みてから閉じてくれますから、データベースを閉じるときには原則としてそちらを使うべきなのですが、ここのクローズ処理ではあえて、無印でエラーが出たならv2を使うという手順を取っています。無印は解放忘れがあるとエラーになるため、不適切なコードが判明しやすいからです。
プリペアドステートメントを作るsqlite3_prepare_v2は、複数のSQL文の連続文字列への先頭ポインタが渡されると、最初のSQL文の切れ目までを処理して、その次の文字へのポインタを第5引数に格納して返します。ですから、上のようにループさせれば、次はそのポインタから始めて同じことを繰り返し、SQL文群全体の終点「\0」で終わらせることができるわけです。SQLiteはどこでSQL文が切れるのかを非常に正確に見分けてくれるので、自分で切り分ける処理を書く必要はありません。
★複数のSQL文連続体を切り分けるには、セミコロンで切ればいいというものではありません。文字列の中にセミコロンが含まれるケースがあるからです。
以上で完成です。正直、拍子抜けするほど簡単でした。これで正規のバインド処理も入れられたわけですから、最初からこれで作ればよかったと思いました。では、余計なコメントを削除して、全体を掲げておきます。
100行を超えてしまいました。sqlite3_execよりも、やはり少し長くなりますね。あちらは複数のSQL文実行時のループ処理を書く必要がなかったので、callback関数を書かなければならないとしても短く済んでいたのです。
使い方はこんな感じです。
①SQL文とプレースホルダ用値をそれぞれwxString型変数に格納。SQL文用変数は常に一つだけにする必要があるが、値用変数はいくつあってもよい。
②MySqlクラスの実体を生成し、メンバ関数SqlExecにそのSQL文と値を引数に与えて実行。
③結果が返るクエリの場合は二次元ベクターメンバ変数resultdataに結果が格納されるので、それをゲッタで取り出す。
これなら、SQLiteのクエリをなでしこやPythonと同じくらい簡潔に書くことができます。当初の目的は達成です。
★SQLを実行するSqlExec関数は、正常終了の場合はSQLITE_OK(0)が、エラーの場合はSQLITE_ERROR(1)が返るようにしてありますから、C言語っぽく
if (q.SqlExec(sql, valword) != SQLITE_OK) {return;}
などと書けば、エラーと同時に中断させることもできます。
★上の例では、結果コンテナresultdataを範囲for文で走査しているので、結果コンテナが空ならばループが走らずループ内のatに達しません。よって、結果が空でもエラーになることはありません。もし結果が1レコードしか返らないことが分かっているためループ処理を行わない場合は、結果を取り出す前に
if (q.resultget().empty()) {return;}
みたいな、結果がなかった場合の処理を書いておかないと、万一resultdataが空だった場合はエラーとなります。
ループによって、複数のSQL文を連続で実行できるようにしてあるので、
といったように、SQL文をまとめて変数に格納して実行することも可能です。これはなでしこならできますし、Pythonでも可能でしょう。
このCDデータベースでは使いませんが、SELECT結果を格納するコンテナが可変のベクターであることを利用して、結果の列数が異なる複数のSQLを一度に実行させることもできます。
これで結果格納用二次元コンテナresultdataには「2列の行」「4列の行」「5列の行」が混在することになりますが、エラーにはなりません。ただ、こんなふうに要素数違いの行を混在させてしまうと、値を取り出すときに一手間必要になるでしょう。例えば、10行目に2個しか値がないのに「q.resultget().at(9).at(4)」などと5列目を取り出そうとすると、当然out_of_rangeになってしまいます。よって、各行にいくつの結果が入っているかをsize()メソッドでいちいち確認してから取り出すなどの処置が必要となります。
クラスのおかげですべてのクエリ処理が短く楽に書けるようになり、その後の作業の大幅な労力削減・時間短縮に繋がりました。改造前のsqlite3_exec版が初めて作ったクラスでしたが、あの程度のものでもクラスというものの威力を感じるには十分でした。C++の参考書に載っているようなクラスは、写経して動かしてみても「う~ん、そんなに便利なのかこれ?」という感じですぐ飽きてしまいましたが、こんなふうに実用的なものを考えて作っていくのはとても楽しく張り合いがありましたし、クラスの便利さを実感できる効果もありました。まあこれが仕事で作らなければならないとなると、楽しさばかりでもないのでしょうけれどもね。
……さて、この下の「実験版」は補足というか蛇足というか、採用していないコードなので、「覚え書きの覚え書き」程度のものになります。
今回のアプリ制作のSQLite操作部分については、上記のコードで十分です。データベース・アプリの中核機能であるとはいえ、ここにばかり時間をかけているわけにもいきません。ただ、「これ、一行でSQLが実行できるように、オブジェクト生成と同時にSQL処理が走るような感じにできないかな?」と思って実験してみたら、何となくうまく動いたようなので、以下に書いておきたいと思います。
★この下のコードもsqlite3_step版に書き換えました(2021年12月)。
こんなふうにしておいて、例えば
などと書けば、SqlExec関数を呼ばなくてもSQLが実行されます。コンストラクタは戻り値を持てないので、このままではSqlExec関数の戻り値である0(正常終了==SQLITE_OK)・1(異常終了==SQLITE_ERROR)を返せませんが、その値はメンバ変数のexecreturnに格納されますから、
というふうに取り出して使うことができます。……まあ一行で書けるとは言っても、こんなのじゃほとんどコスト減になっていないですよねw。
★それに、このままではデフォルトコンストラクタを使ったとき、メンバ変数execreturnがいつまでも-1のままになってしまいます。有効な値を常にexecreturnに代入するためには、SqlExec関数の三つのreturnすべてを「return execreturn = SQLITE_ERROR;」というように、execreturnに代入しながらreturnするような形に書き換える必要があるでしょう。
wxListCtrlのソート機能──自作するしかなかった……
wxWidgetsはかなり行き届いた素晴らしいライブラリだとは思うのだけれど、日本語のまとまった解説書もないし、本家のサイト(英語)では使用例コードをほとんど載せてくれていないので、使い方がよく分からないままになってしまう機能がかなりあります。リストコントロールのソート機能もその一つ。ソート用にSortItemsという関数が用意されており、サンプルプログラムにも実装されているというのに、それを見てもどうも使い方が分かりません。結局は自作せざるを得ませんでした。
★ExcelのVBAマニュアルには、どのメソッドにも短い使用例コードが必ず載っていました。wxWidgetsも、現行のサンプルプログラムみたいな、いろいろな機能を一度に詰め込んだせいでどこを見ればいいのかが分かりにくくなったコードではなく、機能ごとに短いコードで使用例を書いておいてほしいものです。
★wxWidgetsは、10年くらい前の古いバージョンなら、ネット上である程度は日本語解説を読むことができます。反面、新しいバージョンのそれがかなり少ないところを見ると、wxWidgetsは国内ではもうあまり使われていないということなのでしょうか?
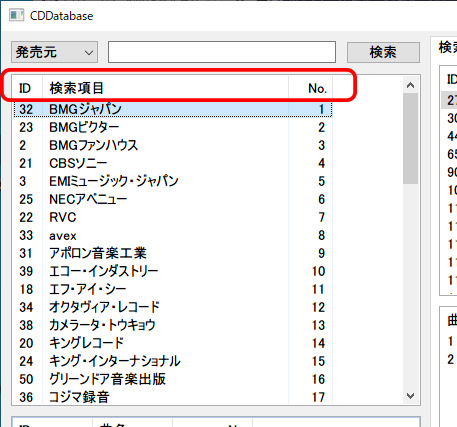
リストビュー1
欲しいのは、ヘッダの部分(上図の囲み部分)をクリックするとその列をキーとして昇順または降順ソートされるという、よくある機能です。「これくらい最初からウィジェットの基本機能として付けておいてほしいな~」とも思うのですが、なでしこ・Tkinter・GTKの類似ウィジェットにもたぶん付いていなかったと思います(ですよね?)。ただ、wxWidgetsのリストウィジェットの場合は、ご覧のようにスクロールバーは初めから付いていますので(横方向のバーも必要なら現れます)、スクロールバーが別部品になっているTkinterとGTKより手間が少なくて済みます。
★今回の制作では、検索画面の結果表示用リストには、リストコントロール(wxListCtrl)の派生クラスであるリストビュー(wxListView)を使っています。この方が選択された行のデータを取得しやすいからです。これらは、左端列だけはなぜか右寄せが利きません(バグ?)。とはいえ、数字であっても左寄せの方が見やすいような気もするので、あまり気にしないようにしています。
ウィジェット上で並べ替える方法が分からない以上、一度二次元コンテナに書き戻してからそこでソートし、それをもう一度リストに書き入れる、という手順を取るしかありません。その程度ならそれほど難しいことはないはずです。次のコードは、リストビューのデータを二次元ベクターに書き戻す処理です。ここでのリストビューは「MyList1」という名前です。
これで二次元コンテナvvに表示データが格納できました。次はクリックされた列を基準にソートする処理です。調べてみると、C++11ではラムダ式が使えるようになったので、sortの比較関数はラムダ式で書くのが当たり前になっているんだとか……。そう言われても、「はあそうなんですか」というか、「ラムダ式? 何それおいしいの?」というか、そんなセリフしか浮かんでこないのですがw、ラムダ式ならキャプチャ機能で(下の[&]の箇所)列番号を取り入れられるので、「ある列をキーとした二次元配列のソート」がすごく簡単に書けるらしい……。簡単なのはいいことですw。それなら、ということで、いくつかのサイトのサンプルを参考に、ラムダ式を見よう見まねで書いてみました。
これで昇順ソートはできるようになりました。降順は、ラムダ式の中の不等号の向きを変えるか、あるいはsortの引数を「beginとend」から「rbeginとrend」に変えることで実現できます。ここでのラムダ式はご覧のようにけっこう長いので、分岐を書くときは後者の方が省エネになるでしょう。
★ラムダ式も今回初めて書きましたが、なるほど確かに便利でした。でも、[]で始まって、[](){}だけで構成されている式(関数オブジェクト?)というのは、書いていて何だか落ち着かない気分にさせられます。「異形のもの」に触れているような感じ?
実は、ここまではそれほど苦労はしなかったのですが、ちょっと時間がかかったのが「昇順と降順の切り替え判定」と「フラグ管理には何を使うか」についてでした。前者については、同じカラムヘッドが連続でクリックされるのなら単純に交替させればいいだけなので簡単なのですが、実際はクリックされるカラムは不規則に変化します。どう処理すればいいのでしょう?……しばらく悩みましたが、実はそれほど難しい問題ではないことにやがて気づきました。「データが不規則に並んでいる状態のソートで、まずなされるべきなのは昇順ソート」なのだから、どこかのカラムヘッドがクリックされたら、そのカラムのみ「次は今のと逆」というフラグを立て、そのほかのカラムは全部「次は昇順」フラグを立ててしまえばいいのです。つまり、あるカラムヘッドがクリックされたら、ほかのカラムはすべて初期化=「次は昇順」状態にするということです。
「次は昇順」フラグ……0(降順ソートされた後と、ほかのカラムヘッドがクリックされたとき)
「次は降順」フラグ……1(昇順ソートされた後)
MyList1は、検索実行時、最初は(0始まりの)1列目、つまり中央の「検索項目」列でソートされます。右の列「No.」はそれに合わせて連番が打たれます。すなわち、MyList1は(0始まりの)1・2列目が連動しているのです。ということは、(0始まりの)1・2列目は常に同じフラグを立てる必要があるということです。
次は、フラグ管理には何を使うか、です。「複数フラグと言えばビット列だよね~」ということで、最初はstd::bitsetのオブジェクトをwxFrame(wxWidgetsアプリの主ウィンドウを司るクラス)継承クラスMyFrameのメンバ変数にして管理しようと思ったのですが、困ったことに、ビットって「右始まり」なんですよね……。カラムヘッドは「左始まり」ですから、bitflg[0](ビット変数)とcolnum[0](選択カラム変数)とでは、添字が指す位置が食い違ってしまうわけです。「00100111」というフラグの場合、bitflg[0]なら右端の「1」、colnum[0]なら左端の「0」と、違う値になってしまいます。これらは見た目が同じになっていてほしいところ。一方の「001」ともう一方の「100」が等しい、というのでは、間違えやすくなります。
ビットを「逆順」にする関数でもあればいいのですが、どうやらなさそうです。自分で書いてもいいのだけれど、それよりも既存の機能の中に、左端が添字[0]になり、0と1を配列で扱えるようなものは何かないだろうかと探してみると……ありました。何のことはない、「文字列」です。フラグ管理に文字列を使うというのはちょっと「ダサい」ような気もしましたが、使えるのならばダサいかどうかなどはどうでもよろしいw。
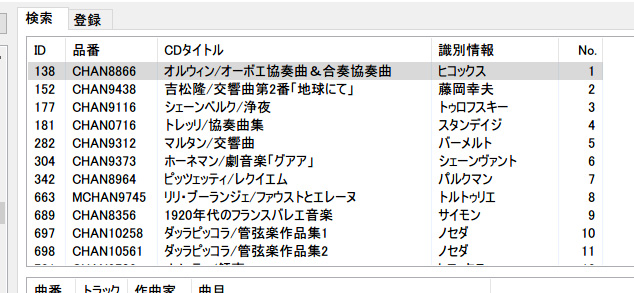
これで完成です。4000行くらいある検索結果リストで、不規則にキー列を変えながら何回もソートしてみましたが、特に矛盾は起こりませんし、速度も問題ありません。無理してSortItems関数を使わなくても十分な性能が得られましたので、「これでよし」ということにしたいと思います。完成版は、MyList1より2列多い5列構成のMyList3の方を挙げておきます。
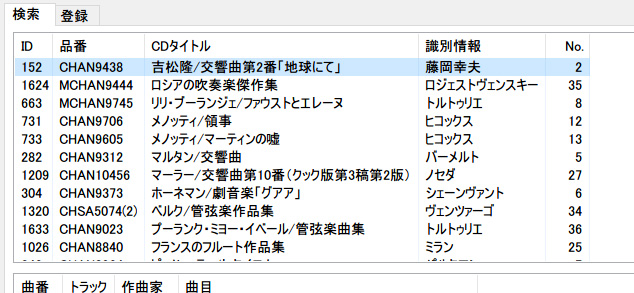
リストビュー3(レーベル名「シャンドス」で検索した結果)
リストビュー3(「CDタイトル」ヘッダを2回クリックして降順にしたところ)
ご意見・ご教示等ございましたら
こちら からお送りください。
Copyright © 2021 鷺澤伸介 All rights reserved.